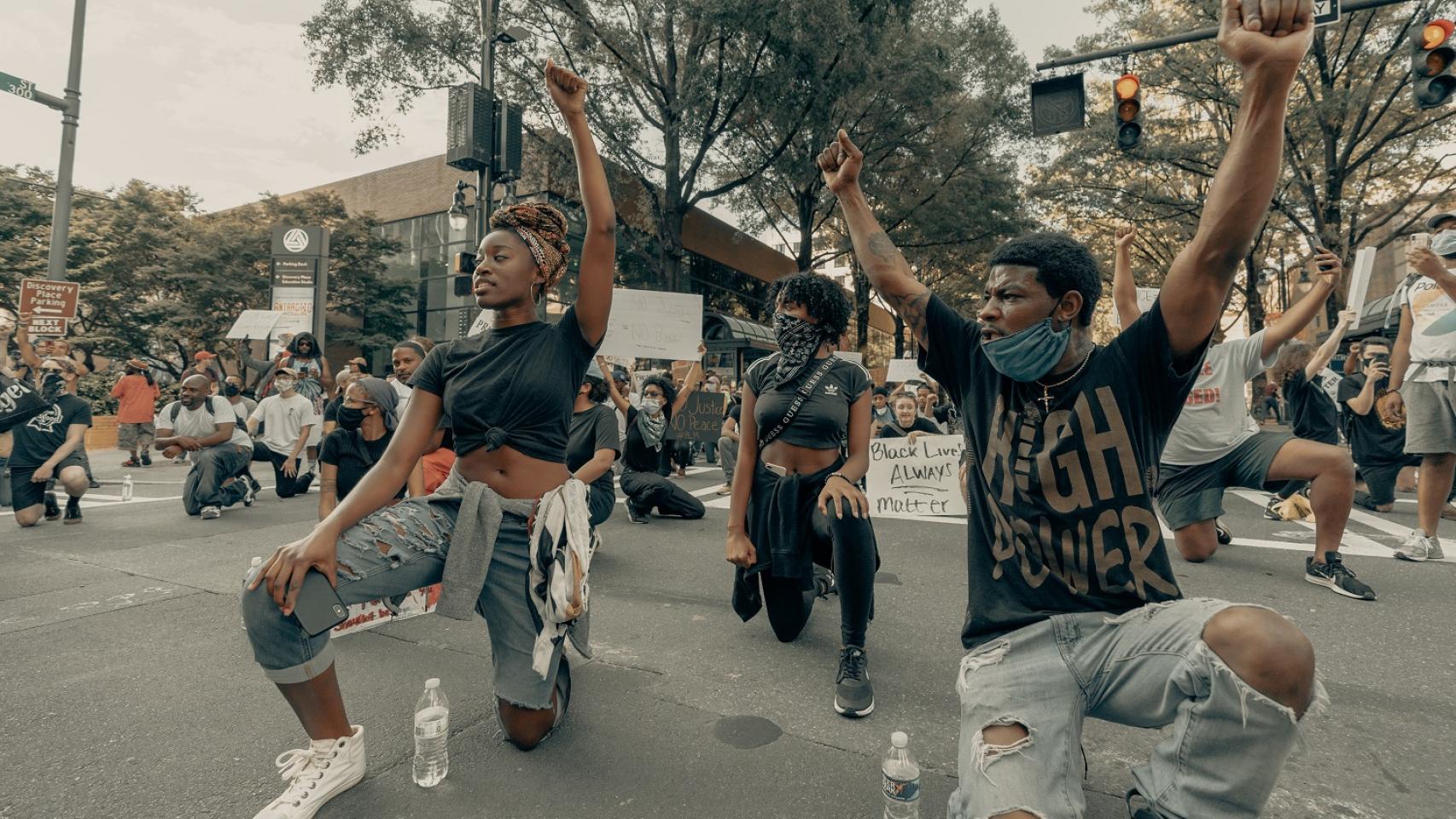
E l pasado 25 de mayo, un hombre negro llamado George Floyd moría en Mineápolis (Minesota). Lo hacía en el suelo, tras haber sido arrestado por cuatro agentes de policía. Uno de ellos, Derek Chauvin, inmovilizó a Floyd presionando su cuello con la rodilla durante más de ocho minutos, mientras el fallecido clamaba que no podía respirar. Un ejemplo de abuso policial en toda regla pero que ha tenido una extensión mucho mayor, hasta el punto de convertir su asesinato en el símbolo de toda una lucha por la igualdad racial en un país, Estados Unidos, que sigue adoleciendo de una discriminación sistemática hacia las minorías impropia de una nación del siglo XXI.
La muerte de Floyd es el resultado de décadas de racismo inherente a la cultura y la política norteamericanas. Al mismo tiempo, reabre el debate sobre estas actitudes en todo el mundo, ya que la discriminación por raza sigue siendo una constante a escala global, también en Europa como se ha constatado con el resurgir reciente de los movimientos de ultraderecha y xenófobos. Pero no podemos olvidar un detalle clave en los tiempos que corren: ese racismo no es exclusivo del plano físico del ser humano, sino que lo hemos extendido y amplificado esta lacra a través de la tecnología.
No en vano, las redes sociales han servido para agitar y movilizar ideologías contrarias a la igualdad racial durante muchos años. Y lo que es más relevante: la inteligencia artificial adolece de sesgos que favorecen esa discriminación de manera constante; en muchos casos incluso de forma inconsciente para los creadores de los algoritmos.
Hemos de remontarnos a 1976 para encontrar la primera mención a los sesgos algorítmicos, planteada por uno de los pioneros de la IA, Joseph Weizenbaum. Desde entonces hasta hoy, cuando la potencia de cómputo ha permitido la democratización de esta tecnología, el debate ético sobre cómo los algoritmos podían perpetuar los estereotipos raciales ha ido cobrando fuerza. Incluso organizaciones internacionales como la ONU o la Unión Europea han planteado guías para evitar que se sucedan estos sesgos y hacer rendir cuentas a los humanos que están detrás de estos sistemas, especialmente cuando su aparición implica decisiones que afectan directa y negativamente a la vida de estos colectivos.
Que nadie se lleve a engaños: los sesgos en la inteligencia artificial son tan viejos como la tecnología misma. De hecho, el primer sesgo detectado en un sistema de IA se creó en los años 70: fue un rudimentario programa de la Escuela de Medicina del Hospital St. George para automatizar la lectura en los procesos de solicitud de admisión. En 1984, se detectaría una grave falta de diversidad entre los alumnos aceptados y, dos años más tarde, la Comisión para la Igualdad Racial de Reino Unido declaró culpable de discriminación racial a esta institución. ¿La causa? El algoritmo tenía en cuenta factores como el nombre o el lugar de nacimiento a la hora de priorizar unos candidatos por encima de otros.
'Negros reincidentes'
En la mayoría de las ocasiones, sin embargo, el racismo expresado en la tecnología no viene marcado por una decisión consciente del desarrollador del sistema, sino que es fruto de un modelo defectuoso o de un entrenamiento del algoritmo con datos sesgados, incompletos o tendenciosos.
Es lo que ocurrió en el caso más conocido de discriminación por inteligencia artificial: el sistema COMPAS. Se trata de un programa de evaluación de riesgos, usado por los jueces de Estados Unidos para predecir la tasa de reincidencia de un criminal y poder tomar así decisiones más fundamentadas en lo relativo a libertades condicionales o permisos penitenciarios. El sistema ya nació con un defecto de base: desde 1920 hasta 1970, la herramienta tenía en cuenta la nacionalidad del padre del criminal a la hora de evaluar su riesgo. Aunque ese factor se eliminó por su racismo obvio, en 2016 la organización ProPublica denunció que COMPAS seguía atribuyendo tasas de reincidencia mucho mayores a las personas negras frente a las blancas. Concretamente, un 77% más de probabilidades, siendo inexactos los resultados en el 80% de los casos.
De los jueces a la policía. La ciudad de Nueva Orleans se alió en la década pasada con la empresa de minería de datos Palantir para crear un sistema de predicción policial, con el fin de anticipar posibles delitos y asignar mejor los recursos policiales. Sin embargo, el sistema falló estrepitosamente, perpetuando los estereotipos sobre la población negra. Todo debido a que el algoritmo usó los datos históricos de detenciones y registros de la policía... la misma que unos años antes había sufrido una profunda investigación por haber acusado en falso a numerosas personas negras e incluso por haberles colocado pruebas falsas a fin de incriminarlos.
El reconocimiento facial
El racismo tecnológico no solo se expresa mediante complejos y arbitrarios sistemas gubernamentales, sino que las tecnologías de empresas privadas también han tenido episodios notables de discriminación hacia las personas que no encajan en el clásico baremo de "hombre blanco". Y entre las distintas tecnologías cuestionadas, el reconocimiento facial se lleva la palma.
Amazon desarrolló un sistema de esta índole capaz de clasificar los rostros de las personas en función de sus rasgos, usado por ejemplo en algunas comisarías de Oregón para automatizar la identificación de sospechosos en registros informáticos. Todo parecía ir bien hasta que un informe del MIT Media Lab (a cargo de la científica Joy Buolamwini) reveló que el algoritmo clasificaba a las mujeres de piel oscura como hombres el 31% de las veces, mientras que las mujeres de piel más clara se identificaron erróneamente sólo el 7% de las veces. Igualmente, los hombres de piel más oscura tenían una tasa de error del 1%, mientras que los hombres de piel más clara no tenían ninguna. Una vez más, la falta de variedad en los conjuntos de datos con los que se entrenó al sistema arrojaba estos resultados.
En una situación más anecdótica, pero quizás más desagradable, se encontró Google. En 2015, la multinacional tuvo que pedir disculpas tras demostrarse que su algoritmo de identificación de imágenes (usado en la app móvil Fotos) reconocía a personas negras como "gorilas". No es el único escándalo protagonizado por la marca de Larry Page: en 2017 conocimos que la Google Cloud Natural Language API realizaba análisis de sentimiento racistas de forma sistemática. Así, por ejemplo, las frases "soy negro" o "soy un judío" eran consideradas más negativas que "supremacía blanca", la cual Google consideraba como neutral. Lo mismo ocurrió con la orientación sexual ("heterosexual" estaba mejor valorado que "homosexual").