
Fotomontaje con el logo de Microsoft. Omicrono
VALL-E, la inteligencia artificial de Microsoft que imita tu voz con solo escucharte 3 segundos
El modelo es capaz de recoger una grabación de apenas unos pocos instantes para imitar no solo la voz, sino sus emociones y ambiente acústico.
10 enero, 2023 11:11Cada vez más empresas se están introduciendo en el mundillo de la inteligencia artificial en España y en el resto del mundo. Ya no hablamos de usar esta tecnología en sus servicios, sino de desarrollar sus propias herramientas, con chatbots como ChatGPT o servicios de mejora de imágenes, como Stable Diffusion. Microsoft es la última en meterse en esta situación, y ha presentado para ello su nuevo modelo de lenguaje: VALL-E.
Este modelo es de naturaleza TTS, es decir, síntesis de voz a texto. En esencia, es capaz de imitar cualquier voz humana prácticamente a la perfección con escasos segundos de exposición a la voz original. Es decir, que sobre el papel y según Microsoft, VALL-E puede imitar estas voces escuchando tan solo 3 segundos de la voz a imitar.
Microsoft deja claro en su web que VALL-E no solo se constituye por sí solo como un modelo de síntesis de voz a texto, sino que engloba aplicaciones de síntesis de voz que se pueden combinar con otros modelos ya conocidos en el mercado, como el ya famoso GPT-3. Eso incluye creación de contenido, edición de voz y aplicaciones de síntesis de voz zero-shot.
VALL-E de Microsoft
Microsoft incluye en su web no solo un esquema de cómo funciona el modelado de lenguaje de códec neural, sino que integra muestras que revelan el propio funcionamiento de VALL-E. Incluye la muestra original de la voz, si no detalles de la misma como su base o sus detalles intermedios, incluyendo su tono. VALL-E recoge todos estos detalles y los imita absolutamente todos, incluyendo la cadencia de la voz.
Además, el modelo es capaz de sintetizar muestras de voz personalizadas con las llamadas seeds propias de VALL-E, lo que permite prácticamente 'transformar' muestras de voces en otras. Tanto es así, que puede sintetizar estas voces personalizadas pero manteniendo la cadencia, el tono e incluso el entorno acústico del aviso del hablante.
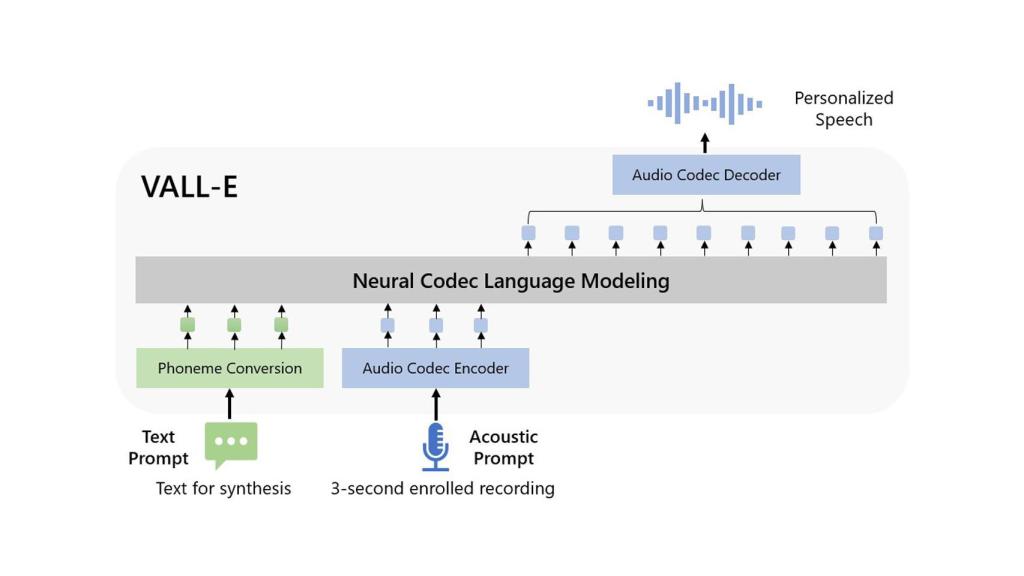
Esquema de VALL-E. Omicrono
Microsoft asegura que también es capaz de mantener las emociones en las muestras de voz originales muestreando indicaciones de audio en una base de datos de voces emocionales. Por otro lado, en las etapas previas de entrenamiento, los responsables de VALL-E escalaron los datos de entrenamiento de síntesis de voz a texto a 60.000 horas de habla en inglés, superando en palabras de Microsoft a los otros sistemas TTS zero-shot ya existentes en el mercado.
Desde que vimos las intenciones de Microsoft de incluir modelos como ChatGPT en servicios como Bing, queda claro que los de Redmond quieren extender su mercado de IA a muchos otros términos. El hecho de que pretenda integrar VALL-E para que funcione con otros modelos generativos podría abrirnos un futuro en el que los servicios de Microsoft estuvieran aderezados por estos modelos en conjunto, formando funciones como pedir a un modelo que imite la voz de alguien en específico.





