
El actual director ejecutivo de DeepSeek, Liang Wenfeng Omicrono
Cómo una 'desconocida' IA china ha desbancado a ChatGPT por sorpresa: todo lo que hay tras el 'bombazo' de DeepSeek
El laboratorio de inteligencia artificial ha adoptado una filosofía completamente contraria a la que han apostado titanes como OpenAI o Meta.
Más información: Los creadores de TikTok van a por ChatGPT: presentan un modelo de IA que 'razona' y superaría a o1 de OpenAI

El sector tecnológico global está sufriendo un terremoto sin precedentes por la irrupción de DeepSeek, la inteligencia artificial china que ha conseguido algo que nadie esperaba: ser más capaz y eficiente que ChatGPT. De un día para otro el chatbot por antonomasia en la carrera de las IAs generativas se ha quedado atrás. Le ha adelantado por la derecha DeepSeek, una solución que proviene de China y que ha causado tal revuelo que hundido a la titánica Nvidia en bolsa, así como ha arrastrado al Nasdaq. Pero ¿qué hay detrás de la IA de DeepSeek y este rendimiento sorprendente que ha hecho tambalear a todo el sector de la IA?
Tanto a nivel tecnológico como respecto a la percepción general, ChatGPT ha sido la herramienta líder de inteligencia artificial. No es para menos; a los pocos días de la llegada de Donald Trump a la Casa Blanca, el magnate anunciaba Stargate, un proyecto que involucraba a la desarrolladora OpenAI y a otras entidades para invertir unos 500.000 millones de dólares en inteligencia artificial. De ahí que sorprenda que un chatbot chino haya conseguido alzarse entre las apps más descargadas de la App Store en apenas unas horas demostrando un potencial generador a la altura de los mejores.
DeepSeek, la empresa con su inteligencia artificial homónima, llega para prometer un chatbot conversacional más eficiente y que apuesta por un modelo de código abierto y totalmente gratuito con lo que ha sacudido la industria cimentada en base a cobrar por el uso de la IA. Y es que cabe tener en cuenta que la empresa china no depende de grandes inversores y su ambición es buscar la ansiada idea de Inteligencia Artificial General (AGI) pero sin las prisas por destacar a nivel comercial que otras como Google, Meta u OpenAI sí tienen.
¿De dónde sale DeepSeek?
Lo más probable es que no le suene el nombre de DeepSeek. Es normal ya que hasta hace escasos días, esta no era más que una compañía china de bajo reconocimiento público que únicamente había publicado un modelo de código abierto el pasado 20 de enero. Éste, denominado DeepSeek-R1, dio mucho de qué hablar por sus capacidades en la comunidad de IA, ya que estaba orientado a resolver problemas complejos usando cadenas de razonamiento.
Pero para entender su ascenso, hay que conocer su pasado. DeepSeek, empresa ubicada en China y totalmente orientada a inteligencia artificial —cuyo nombre comparte con su chatbot— comenzó su andadura como Fire-Flyer, una división de investigación del fondo de cobertura cuantitativo High-Flyer, el más grande de China. Dichos fondos se valen de modelos matemáticos y algoritmos computacionales para sustentar sus decisiones de inversión, de ahí la existencia de Fire-Flyer, según relata una investigación de WIRED.
Vídeo | DeepSeek, la nueva aplicación que altera el tablero de la inteligencia artificial
El actual director ejecutivo de DeepSeek, Liang Wenfeng, fue el mismo que cofundó High-Flyer mientras se encontraba en la universidad. Pronto ganó relevancia, pasando a conseguir unos 15.000 millones de dólares, lo que le hizo destacar entre los especializados. El éxito permitió a Wenfeng fundar DeepSeek en 2023, el actual laboratorio de inteligencia artificial para construir sus propios modelos de IA. Parte de esto fue posible gracias a que High-Flyer ya contaba con equipos especializados para estos fines, con GPUs y ordenadores para analizar datos financieros.
El enfoque de Wenfeng para la fundación de DeepSeek fue diametralmente contrario al que tendría una empresa de IA normal, que en casos normales hubiera buscado posicionar su producto de cara al consumidor valiéndose de personal especializado en ello. Nada de eso; el equipo de investigación principal de DeepSeek estuvo conformado por estudiantes de doctorado de renombre en la comunidad, y que ya tenían cierta fama en los círculos académicos, llegando a ganar incluso premios.

La cuestión es que Wenfeng era el único que sí tenía experiencia en la industria de la inteligencia artificial; de hecho, el propio CEO admitió en 2023 que los técnicos que engrosaron DeepSeek en sus inicios se habían licenciado ese mismo año o en los dos últimos años. La idea de Wenfeng no era aplicar una jerarquía de poder para desarrollar el mejor producto posible, sino instaurar una cultura colaborativa que daba libertad a sus empleados.
Algo que, por otro lado, rompe totalmente con los estándares y entornos laborales impuestos en China, sobre todo las referentes a las tecnológicas del país. En palabras de Wenfeng, su proyecto disfrutaba de una rentabilidad más bien baja, pero disfrutaba de una alta inversión. "La mayoría de la gente, cuando es joven, puede dedicarse por completo a una misión sin consideraciones utilitarias", dijo Wenfeng en 36Kr.
DeepSeek Omicrono
Esta curiosa visión también ayudó a definir la filosofía y características de los modelos de IA que han causado furor esta semana. Y es que DeepSeek no estuvo falta de problemas, debido a la dependencia de las firmas de IA de ciertos componentes clave para el entrenamiento y desarrollo de estos modelos. El más claro ejemplo sucedió en octubre de 2022, cuando Estados Unidos aplicó importantes controles de exportación que impedían a China el acceso a chips de vanguardia especializados en inteligencia artificial.
La idea era sencilla; que estas limitaciones de la administración estadounidense evitasen que China pudiera tener la capacidad suficiente para producir sus propios chips de última generación e impedir que las compañías del país pudieran conseguir el hardware más puntero de Qualcomm, Intel, AMD y por supuesto, Nvidia. De hecho, DeepSeek ya tenía en su haber 10.000 Nvidia H100, gráficas con hasta 175.000 millones de parámetros idóneos para la inferencia de modelos lingüísticos de gran tamaño o LLM.

Ante esta perspectiva y según relata la investigación de WIRED, DeepSeek se tuvo que valer de un importante conjunto de métodos alternativos para poder entrenar sus modelos y que estos pudieran luchar de tú a tú con los más importantes del mercado, apoyados por compañías con un capital sustancialmente mayor. Dichos métodos de ingeniería incluyeron el uso de esquemas de comunicación personalizados entre chips o una reducción del tamaño de los campos para conseguir ahorrar memoria.
Todo este ideario se ve reflejado en los modelos de DeepSeek. Por ejemplo, el modelo DeepSeek-R1 es de código libre y aunque su uso es gratuito, solo cuesta 2,10 euros por el uso de un millón de tokens de salida si el usuario quiere conectar sus propias apps al modelo y a la infraestructura de informática de DeepSeek. En comparación, OpenAI pide 57,80 euros.
Comparativa entre DeepSeek y OpenAI o1 Omicrono
No son ni mucho menos sus únicas bondades; DeepSeek-R1 fue entenado durante 55 días con un presupuesto de 5,57 millones de dólares (unos 5,33 millones de euros al cambio actual) usando 2.048 unidades de procesadores gráficos Nvidia H800. Esto, según el portal The Paper, implica que el coste del modelo representa menos de una décima parte del gasto en el entrenamiento del modelo 4o de OpenAI.
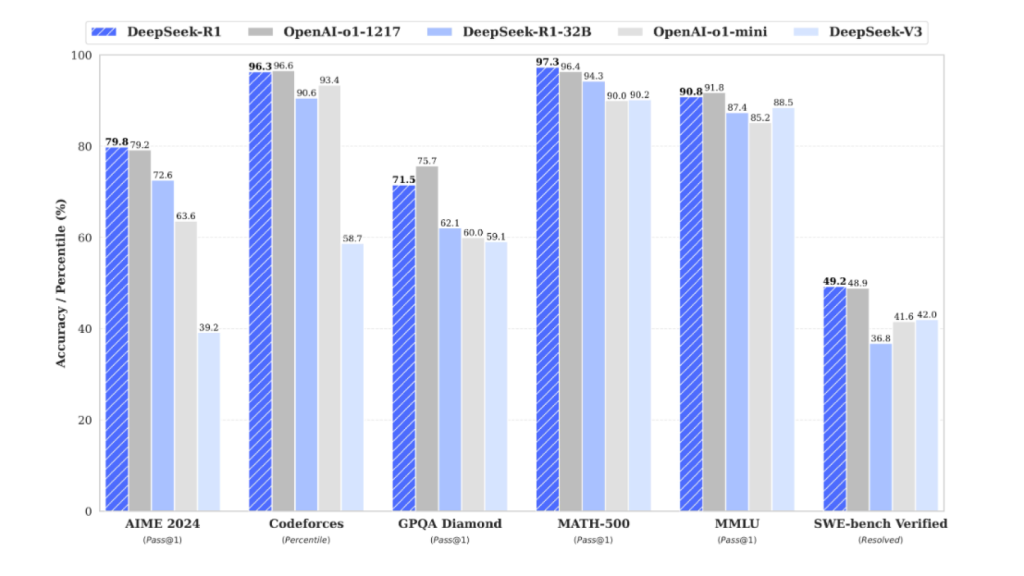
Lejos de lo que pueda parecer, aún con todo DeepSeek-R1 llega a superar a su rival, el modelo OpenAI-o1 en una buena parte de los benchmarks y pruebas de rendimiento del mercado. Desde la presentación de DeepSeek V3 en diciembre del año pasado, la startup china ha conseguido mejorar sus modelos para que sean más eficientes y capaces que los modelos más grandes con una fracción de entrenamiento. Todo ello, recordemos, con 671.000 millones de parámetros.

Incluso DeepSeek V3, el modelo LLM (Large Language Model) anterior a los recientemente presentados por la startup china, superó a sus rivales directos, como son GPT-4o o Llama 3.1 de Meta. Este modelo necesitó 2,788 millones de horas para entrenarse en un proceso que le costó a la compañía 5,5 millones de dólares. En contraposición tenemos GPT-4, el modelo de OpenAI rival en capacidades cuyo entrenamiento costó 80 millones de dólares.
El poder del código abierto
Sin embargo, el aspecto que más refleja la filosofía de Wenfeng y de DeepSeek en sí es que sus modelos —incluyendo por supuesto DeepSeek-R1— son de código abierto. Toda la comunidad de desarrolladores, así como otras empresas, pueden hacer uso del código de estos modelos y descargarlo a voluntad. Además, gracias a esta condición, el propio funcionamiento de los modelos se puede ver de forma clara y transparente, sin secretismos.
🚀 Introducing DeepSeek-V3!
— DeepSeek (@deepseek_ai) December 26, 2024
Biggest leap forward yet:
⚡ 60 tokens/second (3x faster than V2!)
💪 Enhanced capabilities
🛠 API compatibility intact
🌍 Fully open-source models & papers
🐋 1/n pic.twitter.com/p1dV9gJ2Sd
Cualquier desarrollador, empresa o incluso usuario convencional puede descargar el código en GitHub y modificarlo a placer, incluso si este se usa para fines comerciales. OpenAI, Meta o Google toman un enfoque directamente opuesto, en este caso optando por el secretismo y por ocultar en su mayoría las prestaciones internas que hacen posibles a sus respectivos modelos. Empresas que encima son muy superiores económicamente hablando a DeepSeek.
DeepSeek ha seguido sorprendiendo incluso después del brutal éxito que R1 ha tenido en los últimos días, haciendo daño a titanes como Google o Nvidia. El pasado 27 de enero DeepSeek presentó Janus Pro 7B, un modelo multimodal de generación de imágenes que 'entiende' su contenido. Sin entrar en cuestiones técnicas, este modelo que pelea de tú a tú con otros modelos como Stable Diffusion o DALL-E3, supera a sus contrincantes en la mayoría de benchmarks, creando un nuevo estándar de rendimiento de inteligencia artificial.

Janus Pro 7B ha recogido el testigo de sus modelos predecesores y ha destacado por su gran eficiencia, y por no necesitar una importante cantidad de recursos para funcionar. En su interior resalta su sistema de doble vía para procesar imágenes, el modelo es capaz de separar por un lado la codificación para la generación de imágenes y por el otro la propia identificación de la imagen para su recreación. Solo necesita 7.000 millones de parámetros, además. Y sí, también es de código abierto.
Todos estos avances suponen un precedente que Estados Unidos estaba intentando evitar por todos los medios posibles con sus limitaciones en la exportación de semiconductores hacia China —que además, se han visto intensificadas en enero de este año—: que los ingenieros chinos están consiguiendo sortear estas restricciones centrándose en una mayor eficiencia para solventar la escasez de recursos que sufren.

Janus Pro 7B
DeepSeek, a nivel empresarial, resalta porque a diferencia de OpenAI y de otras compañías, no requiere el respaldo de titanes tecnológicos e inversores de gran capital como ByteDance o Baidu, por poner ejemplos locales de China. Si bien es cierto que la creación de Liang Wenfeng ha sido potenciada por la empresa de inversión cuantitativa Huanfang Quant, el laboratorio supone una rebelión contra el stablishment tecnológico que se ha ido generando en torno al auge de la inteligencia artificial; un nuevo jugador que ha puesto patas arriba a Nvidia, Google, Meta y a otras empresas del sector.



