
Mark Zuckerberg en un fotomontaje. Omicrono
La IA que jubilará a los traductores: el nuevo modelo de Meta traduce y transcribe 100 idiomas
La compañía de Zuckerberg presenta un nuevo modelo de traducción automática masiva multilingüe y multimodal que trabaja con texto y voz.
22 agosto, 2023 18:42Dentro de los modelos de inteligencia artificial, existen todo tipo de variantes dedicadas a ciertos fines que cuentan con tanta precisión que los expertos han advertido en numerosas ocasiones respecto a ellos. Especialmente con los modelos de lenguaje, dedicados a la transcripción de voz a voz y de voz a texto, entre otras cosas. Meta acaba de dar un nuevo avance en este sentido, presentando Seamless M4T, un nuevo modelo catalogado por la compañía como un nuevo "avance significativo".
La idea de Seamless M45 es su capacidad de código abierto y a sus características principales. Entre ellas transciende su capacidad para traducir y transcribir cerca de 100 idiomas en texto y voz, proporcionando según recoge la propia Meta en un comunicado "traducciones bajo demanda que permiten a las personas que hablan diferentes idiomas comunicarse de manera más efectiva".
Y es que Meta expone cómo SeamlessM4T reconoce implícitamente "los idiomas de origen sin la necesidad de un modelo de identificación de idioma separado", consiguiendo combinar capacidades de traducción y transcripción en un único modelo específico.
El nuevo modelo de Meta
SeamlessM4T es el nombre que se le ha dado a este modelo, y que significa "Traducción automática masiva multilingüe y multimodal". Para acciones de voz a voz y de texto a voz, puede reconocer 100 idiomas de entrada y convertirlos en 35 idiomas de salida. Está publicado bajo la licencia Creative Commons CC BY-NC 4.0, es decir, está disponible en código abierto.
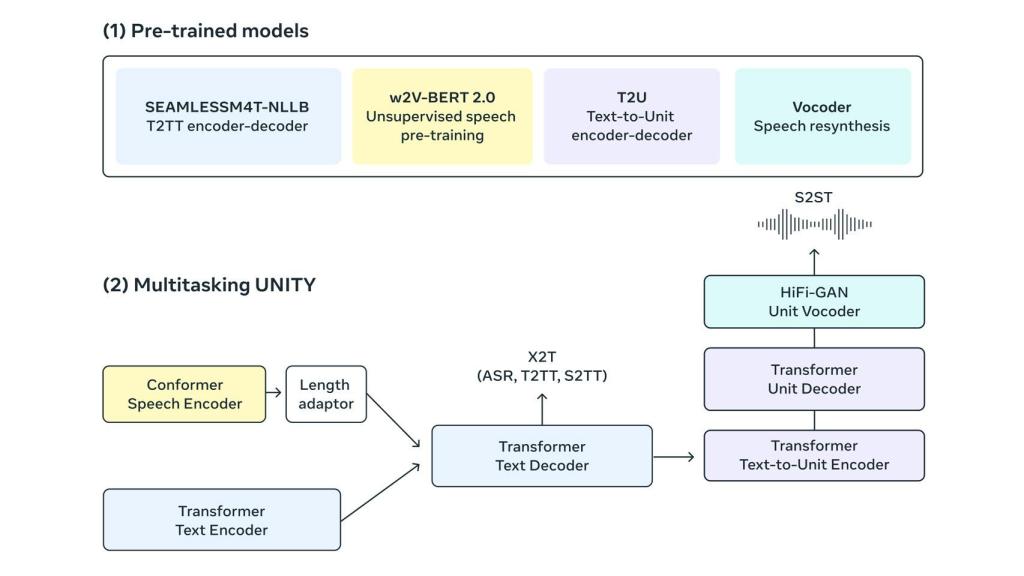
Esquema técnico sobre el carácter multitarea del modelo. Omicrono
Esta es sin duda una de sus mejores bazas. En un vídeo muestra como el modelo es capaz de diferenciar perfectamente idiomas como el télugu (que se habla en una región de India), el inglés o el indio. Todo ello de forma muy precisa y veloz, permitiendo a personas multilingües poder expresarse en varios idiomas sin que el modelo se equivoque al reconocer cual está usando en este momento.
Meta asegura que para construir Seamless M4T, la compañía rediseñó su kit de herramientas de modelado de secuencias Fairseq, con la idea de crear modelos que fueran más ligeros y sobre todo que fueran capaces de manejar mayores cantidades de información en su entrenamiento.

Esquema del modelo de Meta. Omicrono
Además, en pleno desarrollo, crearon un sistema capaz de identificar palabras sensibles o calificadas como tóxicas. Las traducciones de estas palabras pueden incitar, según Meta, al odio o a la violencia de cara a su uso en el día a día. Lo que se busca con este sistema es detectar cuando una traducción introduce estos elementos problemáticos, no presentes en el material original a traducir y así no cometer errores graves.
Lo mismo ocurre con los conjuntos de datos que traducen de forma errónea palabras de este estilo. Los investigadores detrás de SeamlessM4T se empeñaron en revisar los conjuntos de datos que contenían estas traducciones para filtrar "la toxicidad desequilibrada" en los datos de entrenamiento. Si en dichas secuencias se encuentran "diferentes cantidades de toxicidad", quedaban eliminadas (aunque en la versión de código abierto del modelo no está presente este filtro).
[Llega GPT-4, el nuevo modelo de IA que ahora opera como un humano y entiende imágenes]
Otro punto a destacar son los sesgos de género. En un mundo cada vez más inclusivo y que contempla un abanico de condiciones de género más amplio, es importante reconocer estos sesgos potencialmente dañinos. Meta asegura que el modelo puede cuantificar el sesgo de género y verificar si una oración, por ejemplo, usó formas de género concretas de una palabra.
Es el caso de la palabra "doctora", por ejemplo. Al detectar esta forma de género de una palabra, puede asignar un pronombre adecuado (en este caso femenino) en un idioma de destino sin una gramática de género equivalente si es necesario. SeamlessM4T cuenta en una traducción cuántas veces se agregan palabras de género en términos que no tenían género específico en su idioma original.

Inteligencia artificial. Omicrono
De esta forma, el modelo reconoce cuando de forma automática una traducción asume un género en una palabra cuando en el idioma original no tiene una distinción de género, como es el mismo caso de la palabra "médico" en inglés. La forma de tratar este tema para con el modelo es similar al de la toxicidad, de hecho.
Eso sí, Meta admite que su modelo no está exento de sesgos no solo relacionados con el género, sino con la raza. Estudios como el publicado por "The Proceedings of the National Academy of Sciences" expresó como estos sistemas de reconocimiento de voz tenían muchas más probabilidades de transcribir incorrectamente audio proveniente de personas negras frente a personas blancas.
[¿ChatGPT es de izquierdas? Desvelan las tendencias políticas de las inteligencias artificiales]
Meta, en su documento técnico, revela que SeamlessM4T "sobregeneraliza a formas masculinas cuando se traduce desde términos neutrales", y funciona mejor cuando se traduce desde la referencia masculina para la mayoría de los idiomas. Pese a lo dicho anteriormente, Meta ha expresado cómo SeamlessM4T prefiere traducir de forma masculina aproximadamente un 10% de las ocasiones, seguramente debido a una "sobrerrepresentación del léxico masculino", aseguran desde la compañía.
A la hora de entrenar el modelo, Meta explicó que extrajo texto disponible únicamente de forma pública ("decenas de miles de millones" de frases) y voces de Internet equivalentes a 4 millones de horas. No obstante, Meta se negó a revelar las fuentes de sus datos, tal y como recoge TechCrunch.

mark-zuckerberg
SeamlessM4T se podría considerar como la evolución lógica de anteriores modelos de la propia compañía, como No Language Left Behind (un modelo de traducción automática de texto a texto) o Universal Speech Translator. Este último fue uno de los pocos sistemas de traducción directa de voz a voz que admitía el idioma hokkien taiwanés, o también conocido como el min nan taiwanés, una variedad del min nan oriundo de la zona de Taiwán.
El uso del modelo de Meta
Actualmente, tanto Meta como otras tantas empresas usan moderadores humanos para traducir y regular una ingente cantidad de publicaciones en sus redes sociales en cientos de idiomas distintos. Los idiomas menos comunes tienen, lógicamente, a equipos de usuarios menos voluminosos, recurriendo usualmente a herramientas de traducción y moderación automatizadas que no funcionan como deberían.

Mark Zuckerberg.
Este es uno de los posibles escenarios que Meta contempla con SeamlessM4T. Eso sí, desaconsejan el uso del modelo para traducciones que requieran de una certificación directa, además de traducciones de amplio formato. Lo mismo ocurre para campos sensibles, como el de la medicina o el del derecho, ya que el uso de estos modelos todavía imperfectos podría acabar en mala praxis por parte de sus usuarios.
A todo esto se le suma el hecho de que a la hora de traducir un texto, es importante mantener un nivel de riqueza léxica, algo muy visto por ejemplo en ciertos campos, como el de la traducción de idiomas en el mundo del doblaje. Los traductores humanos pueden tomar decisiones de traducción muy concretas que busquen un fin concreto, algo que se puede perder con estos modelos.





