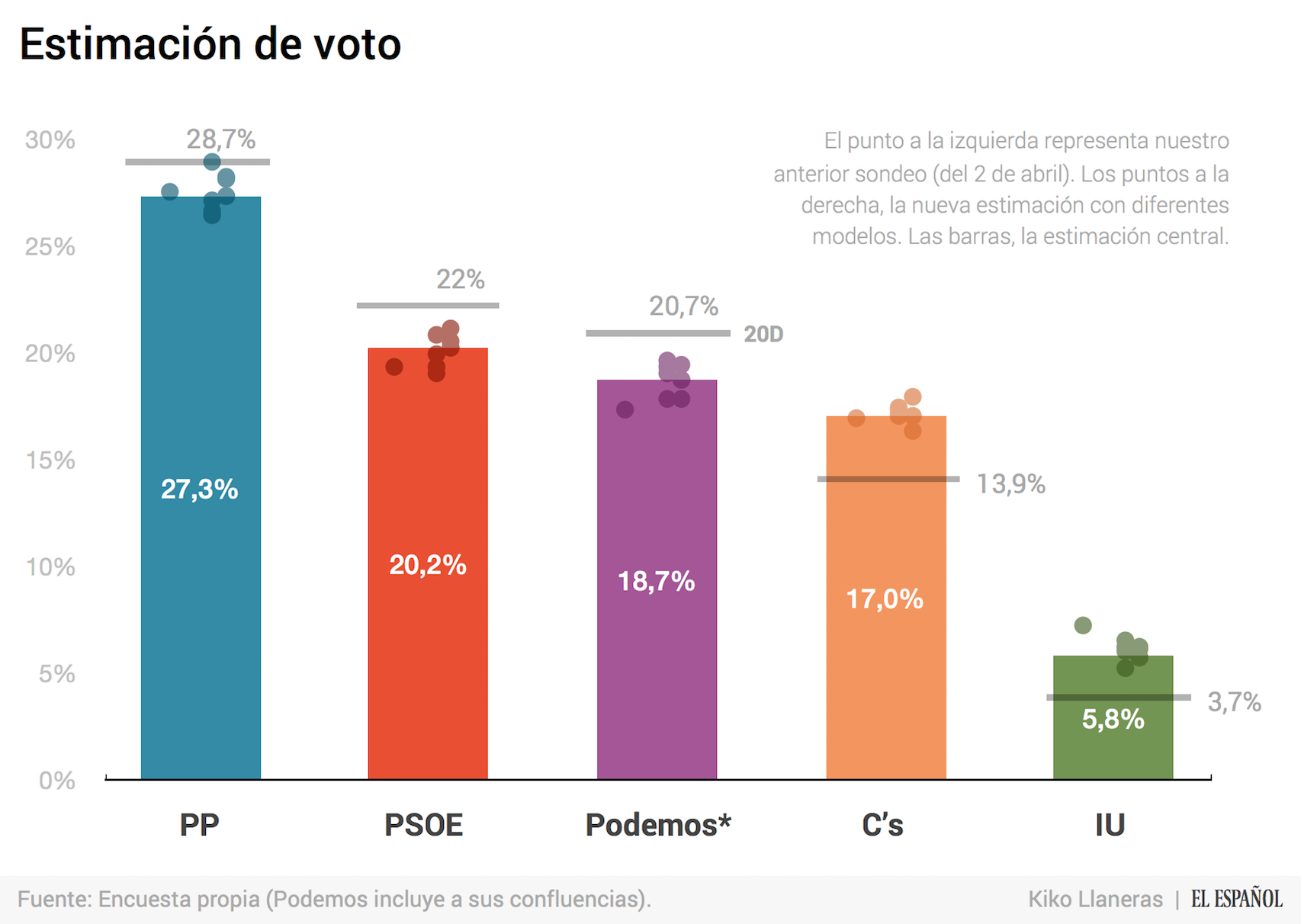
De acuerdo con nuestro último sondeo, si mañana se celebrasen elecciones, el PP lograría alrededor del 27,3% de los votos, el PSOE el 20,2%, Podemos el 18,7%, Ciudadanos el 17%, e Izquierda Unida el 5,8%. El gráfico siguiente compara diferentes estimaciones con los resultados del 20 de diciembre.
Comparativa de la estimación de voto actual con la del 2 de abril.
Respecto a nuestro sondeo del mes pasado, el PSOE ha recuperado 1 punto y Podemos 1,4. Esas subidas penalizan a IU, que cae del 7,3% al 5,8% de voto estimado. PP y Ciudadanos permanecen planos: el partido de Mariano Rajoy supera el 27% y el de Albert Rivera se consolida cerca del 17%.
Si comparamos estos datos con los resultados de diciembre, los partidos que caen son el PP (-1,4 puntos), el PSOE (-1,8) y Podemos (-2). Suben Ciudadanos (3,1) e Izquierda Unida (2,2). Pero es pertinente mantener la precaución con las subidas de estos dos partidos. Como ya expliqué, es posible que los encuestados estén siendo 'expresivos' en los sondeos, pero que enfrentados a las urnas acaben votando a PP, Podemos o PSOE —movidos por lógicas de coaliciones y votos útiles—. Cabe tener en cuenta también la experiencia de la última campaña. Entonces fue Podemos el partido que subió más durante las últimas semanas. Y Ciudadanos el que más cayó. Además, tanto el PP como el PSOE mejoraron los pronósticos y obtuvieron unos resultados mejores que los que presagiaban las encuestas. Estas dinámicas podrían repetirse o no. Juzgarlo depende del lector.
Las transferencias de voto
La encuesta informa también sobre las transferencias de voto. El gráfico siguiente muestra a quién votarían hoy quienes en diciembre votaron por PP, PSOE, Podemos, C's e Izquierda Unida. Así podemos ver la fidelidad de cada partido y los trasvases entre unos y otros.
Perspectiva de la transferencia de votos.
El Partido Popular es el partido con mayor fidelidad, seguido (probablemente) de Izquierda Unida. Los datos de nuestro último sondeo sugerían que Podemos tenía una baja fidelidad. Ahora, en cambio, aparece similar a la de PSOE y Ciudadanos. No obstante, Podemos todavía sufre un hándicap respecto a estos dos: tiene menos ex votantes indecisos (de los que a menudo acaban repitiendo su voto).
La tabla ayuda también a explicar las subidas de Izquierda Unida y Ciudadanos. La coalición de izquierdas crece porque recibe el 10% de los votantes de Podemos de nuestra muestra. Ciudadanos crece porque captura un 7% de los ex votantes del PP y un 8% de los del PSOE. Son datos aproximados —por los márgenes de error de un sondeo de 1.000 entrevistas—, pero seguramente indicativos. La tabla muestra también que PSOE y Ciudadanos son los partidos con más indecisos: un 6% y un 8% de sus ex votantes, respectivamente, no sabe a quién votaría hoy.
Haciendo distintas cocinas
En el primer gráfico he incluido media docena de estimaciones distintas. Las barras representan mi estimación central y cada punto el resultado de aplicar un modelo de estimación ligeramente distinto. Los detalles de cada uno los tienen a continuación.
Muestra realizada con 1.000 entrevistas.
AG. Esta estimación es la menos sofisticada y la menos confiable. Resulta simplemente de ponderar los resultados agregados de la intención directa de voto por el recuerdo de voto.
M9, M1. Estimaciones de voto ponderando las 1.000 observaciones para ajustar el recuerdo de voto de la muestra a los resultados de las elecciones del 20 de diciembre de 2015. Un modelo hace el ajuste al 90% y el otro completamente. Estos modelo y todos los que siguen están ponderados también para que la muestra sea representativa por edad, sexo, nivel de estudios, situación laboral y CCAA. Además, he asumido que los partidos pequeños (ERC, DL, etc.) repetirán sus resultados del 20 de diciembre, porque nuestra muestra es insuficiente para estimarlos.
M9L, M1L. Igual que los anteriores, pero incorporando un modelo de «voto probable». Asumo que los indecisos entre dos partidos tienen un 50% de probabilidad de votar a cada uno. También que quienes declaran una baja probabilidad de votar no votarán. Finalmente, reduzco a la mitad la probabilidad de votar de los entrevistados que, preguntados por su voto del 20D, prefieren no contestar o afirman que votaron en blanco o no votaron.
F. El último modelo usa los mismos ajustes que M1L, pero fusiona las 1.000 entrevistas más recientes con las 1.000 entrevistas de la encuesta que publicamos el 2 de abril. Las entrevistas de ambas encuestas están ponderadas para que la más reciente tenga un peso de dos tercios.
Como ya expliqué, mi propósito es mantener varios modelos para ofrecer una medida de incertidumbre. Por el mismo motivo, he añadido a la tabla el error por muestreo. Veréis que el porcentaje de voto de cada partido puede moverse fácilmente en un intervalo de ±1%.
De las seis estimaciones, las que considero centrales son las de M1L y F. El primer modelo es más ágil porque sólo usa entrevistas de esta semana. El segundo es más lento y puede capturar con retraso los últimos movimientos, pero a cambio reduce el error por muestreo. Tiendo a pensar que los votantes se habrán movido relativamente poco en estas semanas, así que la estimación del modelo fusionado me gusta especialmente.
Mañana podrán leer la tercera y última entrega del sondeo electoral de EL ESPAÑOL.
FICHA TÉCNICA
Se han realizado mil entrevistas a partir de un panel online. Netquest ha proporcionado los datos en bruto a EL ESPAÑOL. Kiko Llaneras ha calibrado la muestra y producido las estimaciones. En los próximos días se compartirán los 'microdatos' del sondeo con las mil entrevistas para que cualquier persona interesada —académicos, otros medios, o los propios lectores– puedan usar las cifras para hacer sus propios cálculos o responder otras preguntas.
Trabajo de campo. Entrevistas a partir de un panel online de captación activa (sólo por invitación) certificado con la norma ISO026362. El trabajo de campo lo ha realizado la empresa Netquest.
Tamaño de la muestra. 1.000 entrevistas online obtenidas con cuotas por sexo, edad, provincia, tamaño de hábitat, nivel de estudios y situación laboral.
Ponderación. Los datos brutos han sido ponderados para calibrar por variables sociodemográficas: sexo, edad, hábitat, estudios, situación laboral, y el cruce de sexo y edad. La calibración consiste en aplicar un algoritmo de raking que pondera cada observación —cada uno de los 1.000 entrevistados— para ajustar, a unos valores de referencia, las distribuciones marginales de esas variables en la muestra. Los valores de referencia los hemos tomado de la Encuesta de Población Activa y del Censo Electoral (INE). También hemos ponderado los datos con el mismo proceso para ajustar el recuerdo de voto de la muestra a los resultados de las elecciones del 20 de diciembre de 2015.
Estimación de voto. Para producir las estimaciones de voto hemos usado diferentes modelos. Todos los modelos utilizan datos ponderados por las variables sociodemográficas y para ajustar el recuerdo de voto. algunos modelos de estimación tienen en cuenta también la probabilidad de votar que declara cada entrevistado. El detalle de cada modelo de estimación puede leerse en el artículo.
Ámbito. Nacional.
Universo. Población española de 18 años y más.
Error muestral. Para un nivel de confianza del 95,5%, el margen de error de la muestra es del ±3,1%.
Realización del trabajo de campo. Del 18 al 22 de abril de 2016.