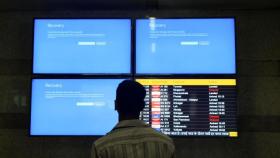
La pantalla azul de Microsoft en el aeropuerto de Madrid-Barajas. Omicrono
Por qué las grandes empresas no tienen infraestructura propia para evitar apagones: "No es práctico ni económico"
La caída de Azure ha impactado en empresas de todo el mundo pero, ¿por que existe esta dependencia para tantas empresas a nivel mundial?
20 julio, 2024 02:52Este viernes a primera hora se producía el caos. Al borde de las 8 horas un pequeño archivo en una actualización de seguridad de los sistemas de CrowdStrike tumbaba los servicios de la nube de Microsoft Azure provocando el colapso de los sistemas de cientos de compañías, hospitales o bancos de todo el mundo. No ha sido hasta cerca de las 13:30 horas de España cuando la situación volvía a la normalidad.
El cataclismo digital se ha producido por la escasa comprobación de CrowdStrike antes de realizar una actualización de seguridad en el sistema EDR, que sirve para proteger equipos e infraestructuras de empresas. Este sistema ha fallado y ha derivado en una congelación instantánea de máquinas y ordenadores de Azure, la nube de Microsoft mostrando un pantallazo azul de Windows e impidiendo así desde el trabajo en oficinas a que aviones pudiesen despegar hasta que los usuarios pudiesen realizar operaciones bancarias.
Además de sufrir las consecuencias de la forzada desconexión digital, este fallo evidencia la hiperconexión y la dependencia de cientos de compañías en todo el mundo de los mismos proveedores, que se reparten principalmente entre gigantes de internet como Microsoft, Google o Amazon. Ante esta situación, cabe plantearse si esto podría haberse evitado e ir incluso más allá, ¿por qué las empresas no cuentan con sus propios desarrollos que les permitan aislarse en caso de un fallo global de este tipo?
"Lo que estamos presenciando es una crisis significativa en el ámbito digital. Cuando en la cadena de suministro digital un proveedor de servicios se ve afectado, toda la cadena puede romperse, provocando interrupciones a gran escala. Este incidente es un claro ejemplo de lo que podría denominarse una pandemia digital: un único punto de fallo que afecta a millones de vidas en todo el mundo", explica Chris Dimitriadis, director de estrategia global de ISACA en declaraciones a EL ESPAÑOL - Omicrono.
Dimitriadis expone que no se trata exclusivamente de una interrupción digital, sino que es un problema de alta gravedad que va más allá de las operaciones empresariales pues afecta a las vidas de las personas: "los médicos no pueden ver a sus pacientes, los medios de comunicación no pueden emitir noticias y los viajeros se quedan tirados en los aeropuertos".
Hiperconexión y dependencia
El ejectivo expone que el riesgo de concentración surge cuando demasiadas empresas dependen de un solo proveedor de varios productos y servicios, "lo que las hace vulnerables a ese único punto de fallo. Este tipo de interdependencia puede significar que incluso pequeños choques pueden tener efectos enormes, a veces no solo para unas pocas empresas, sino para industrias y economías enteras".
Una reflexión compartida por Sancho Lerena, CEO y fundador de PandoraFMS, que insiste en que "el problema es que hay una dependencia tecnológica enorme de proveedores como Microsoft o CrowdStrike. No debería haber ocurrido esto simplemente porque hay muchas alternativas, y algunas europeas".
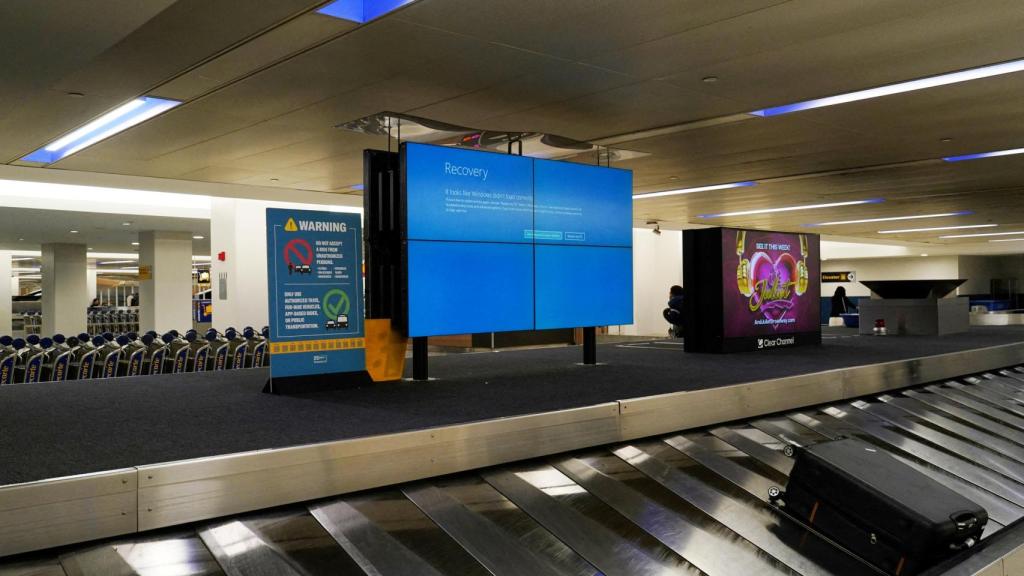
Pantalla azul de Windows en aeropuerto. Omicrono
Lerena ejemplifica la necesidad de las empresas de que todo esté conectado que "exige mantener una infraestructura tecnológica muy compleja, tanto, que hace falta externalizar ciertas cosas porque es todo tan hiper especializado que tienen que tienen que comprar productos de terceros para hacer ciertas cosas", sin embargo Lerena habla de la perversión del modelo por la comodidad de las empresas: "la gente acaba comprando soluciones que no necesita".
"La gente dice, lo quiero todo y a tope. Le da que sí a todas las casillas e instala por defecto lo que viene en sus máquinas y sistemas operativos. Cosas que igual no necesita porque ni entienden lo que hacen, pero como están disponible aceptan y no asumen que cuanta más complejidad en un sistema, más posibilidades hay de que falle. Todo el mundo va comprando tecnología porque quiere más y estar más protegidos, pero no asume que eso hay que mantenerlo y gesionarlo. A más 'piezas' más puede fallar".
En este sentido Dimitriadis explica que la estrategia más efectiva es la gestión de riesgos en la cadena de suministro. "Nunca ha sido más importante; cada organización necesita comprender sus dependencias y desarrollar planes de contingencia para mejorar posibles vulnerabilidades".
¿Y una infraestructura propia?
Ante esta dependencia de proveedores y soluciones de terceros "se pueden tomar medidas para diversificar la infraestructura y reducir la dependencia de un solo proveedor o servicio. Pero revertir la hiperconectividad es muy difícil", expone por su parte Rodrigo Moro, experto en cloud computing y profesor en Immune technology Institute, quien argumenta que las empresas "se conectan o contratan estos servicios para disfrutar de recursos e infraestructura que sería impensable adquirir o desarrollar".
Es decir, no pueden dedicar inversiones a tener todo el sistema, sino que deben "diseñar servicios y, en general organizaciones, más resilientes", comenta a este periódico el director del área de seguridad y privacidad de Gradiant, Juan González. La resiliencia es la capacidad de un sistema para continuar funcionando y recuperarse ante una incidencia grave como la ocurrida, manteniendo los servicios esenciales en funcionamiento.
Una idea que abraza Dimitriadis que expone que para "mitigar el riesgo de suministro no debe centrarse solo en los específicos de los proveedores, sino también incorporar las interrupciones generales de la cadena de suministro y su impacto total en la empresa", además explica que también es importante el realizar evaluaciones y monitoreo constantes, diversificar proveedores así como establecer contratos firmes que respalden a la compañía ante cualquier interrupción.

Pasajeros con el sistema de Barajas caído. Omicrono
Otro de los escenarios a la que pueden acogerse muchas empresas es a no estar completamente hiperconectados, expone Lerena. "Desde el punto de vista de seguridad es lo más recomendable", un escenario complicado que exige un mayor esfuerzo —a todos los niveles— y que está muy asentado en el sector. "La gente lo quiere hacer por comodidad y porque las prácticas de la industria están contaminadas por intereses comerciales", asegura.
Moro por su parte cree que aunque es posible "y muchas veces la única opción para cumplir con la regulación vigente, tener su propia infrastructura no es práctico ni económico para la empresa. Requiere inversiones enormes". Tesis que apoya González, quien explica que "Desarrollar una infraestructura propia conlleva unos altos costes (desarrollo, mantenimiento, actualización…) y exige disponer de personal altamente cualificado, que para las empresas no tecnológicas es muy complejo de atraer y mantener. Además, contar con infraestructura 100% propia tampoco elimina los riesgos al 100%".
"Pasará, cada vez más"
El fallo que ha bloqueado a empresas de medio mundo en la mañana de hoy es complicado que vuelva a pasar, pero puede volver a pasar. De hecho, el fundador de PandoraFMS es tajante: "esto va a pasar, y cada vez más. Porque dependemos de cuatro gatos. Las empresas tienen que reconsiderar sus políticas de seguridad y sus proveedores. No podemos permitir que nuestra independencia tecnológica dependa de empresas sobre las que no tenemos ningún control".
En esta ocasión el fallo se ha debido a un error, pero ha mostrado la debilidad del sistema conectado, revelando el camino a los ciberdelincuentes del impacto que puede tener un ataque a ciertos proveedores de los que dependen muchas empresas clave.
Sistema de cambio en Estambul sin funcionar. Omicrono
"Aunque el incidente de Crowdstrike se atribuye a un error, podría haber sido un ciberataque destinado a aprovechar vulnerabilidades en el proceso de actualización de software, lo que puede llevar a compromisos de sistemas, robo de datos y pérdida de datos con implicaciones para la seguridad nacional", explica el directivo de ISACA.
Ante la ausencia de "soluciones mágicas" inmediatas que permita evitar que algo similar suceda de nuevo, González explica que es posible establecer desde ya una serie de controles que "reduzcan o bien la posibilidad de que se repita o el impacto en caso de que ocurra. Por un lado, se pueden establecer, y ya se hace, obligaciones a las empresas proveedoras para que lleven cabo mejores prácticas de gestión de cambios y pruebas más rigurosas antes de las actualizaciones. Esto puede incluir compensaciones económicas ante incidentes como el ocurrido. Por otro lado, se deben establecer mecanismos para responder de forma rápida y efectiva ante este tipo de incidentes, como ha sido el caso de hoy".